Run length encoding
Run length encoding is the simplest form of compression, in fact it's so simple that doesn't even need proper introduction. We can avoid discussing what kind of data we want to compress and we don't have to introduce new concepts like entropy. If you ask a layman how compression works, his answer will probably be some sort of RLE method.
RLE
Let's jump right into it. We can replace any repeating occurances of a letter with its repeat count, which means instead of lots of repeating characters, we'll have only two: the character itself and the count. For example this:

turns into that:

You can see it in action below. Can you break it?
Compressed text:
Decompressed back:
So, this method has a critical flaw, when you enter a numerical digit as input, it will be interpreted as a number in the decompression phase and will mess with the repeat counts. We haven't specified that our input can't contain any numbers, and we shouldn't: compression methods will likely be used on binary data, where every byte can have a value from 0 to 255. So what can we do to fix this?
- Store the repetition count for each letter. In the earlier example this count had a dynamic size, for example 10 took two characters of space. We could store an arbitrarily high count this way, but usually a fixed size is easier to work with. It depends on your data, but it's rare to see a byte repeated 200 times so it might come as a surprise that we will still reserve a whole byte for storing this count. Because of that we won't have to bother with shifting and reassembling bytes when we read our next value.
- As you can see, this way the file can become way larger than the original, if the repetitions are sparse enough. We wanted compression, but we ended up exploding our file. If only there was a way to turn this whole procedure off for specific chunks of the file. We have to utilize an additional byte or bit for this, if this flag is true, then the next few values will be interpreted as if they were compressed, otherwise as raw values.
- We can do this repetition detection a bit smarter, and this way we can avoid this whole mess of additional flag bits. For example, with N = 3, we can do the following: For repetitions larger or equal to 3, we'll write the repeating byte 3 times, and then the count. For repetitions with size 1 or 2, we just use the raw values. This also has the side effect of negative compression, but only for repetitions with size 3. You can also tweak this parameter N according to your needs.
What happens if we pass this fixed size limit and we have a byte repeated 257 times? It's simple, we just start a new block. You can see this in action right below. Since the counts are stored as raw byte values, they won't always have valid ASCII counterparts. To make the visualization nicer, I encompassed these numbers with parentheses. You can attempt to break it, but note first, that the decompression will use the underlying byte values instead of parsing the displayed string.
Compressed text:
asdasd
Decompressed back:
So for N=3, this:

compresses to that:

The testing area below uses the same (count) notation shown earlier:
Compressed text:
asdasd
Decompressed back:
Repetition count zero
We can see that the repetition count of zero has no use in the previous examples. How can we use this extra value? We can store an extra repetition count, or maybe more in the last case. As the compressed version of CCCCCCCC (8 times C), instead of CCC8, we can write CCC5 (5 = 8-3). This way we can save a few bytes for longer counts.
Binary RLE
If we restrict the range of values to two (so instead of letters and numbers, we'd only be dealing with 0s and 1s, for example), we can simplify the matter quite a bit. An example of this is black (0) and white (1) pixels on a faxed image.
 What this compression method does is that instead of storing the values themselves, it assumes that the data will start with a white pixel, and only stores the number of repetitions until a black pixel comes. If we follow the example above, the first number would therefore be 3. The next number will simply be the amount of black pixels, then the amount of white ones, you can probably see the pattern by now. If our data starts with a black pixel, we simply put a 0 as the first number, showing that there are zero white pixels at the beginning.
What this compression method does is that instead of storing the values themselves, it assumes that the data will start with a white pixel, and only stores the number of repetitions until a black pixel comes. If we follow the example above, the first number would therefore be 3. The next number will simply be the amount of black pixels, then the amount of white ones, you can probably see the pattern by now. If our data starts with a black pixel, we simply put a 0 as the first number, showing that there are zero white pixels at the beginning.

You can see this below on a black and white image encoded in row major order (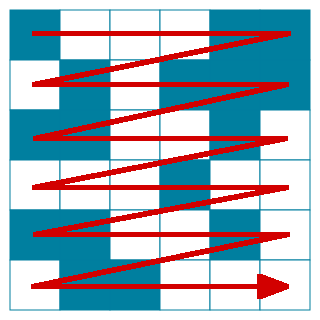 ). Click on the tiles to change their values.
). Click on the tiles to change their values.
A concrete example: the TGA format.
RLE has its use in real world applications as well. Even if you haven't heard about the TARGA format, you probably had used JPEG in the past, which also utilizes some sort of RLE. Here's an example file to show how it's done.
I'm not going to delve deep into the TGA specification, but here are the most important bits of the header (first 18 bits in this case):
hexdump -C -n18 smiley.tga
00 00 0A 00 00 00 00 00 00 00 40 00 40 00 40 00 18 20
- 0A: indicates RLE compression and true color (no colormap).
- 00 00 40 00: image offset. For some reason TGAs start at the bottom left corner by default, so we offset it by the height of the image (64 pixels (0x40)).
- 40 00 40 00: image width and height (64x64).
- 18: 0x18 = 24 bits per pixel. One byte of Red, Green and Blue.
- 20: ordering, since we start at the top left corner, we also have to reverse the vertical direction.
After the header comes the image data. As you can see the image has parts with large patches of a single color, and gradients where the neighboring colors all differ from each other slightly. So, how does our compression handles this?
The method is similar to PackBits. Basically we sacrifice one bit from our count byte in order to indicate compression. If that bit is active, it indicates compression, the next byte (19) must be repeated 5 times. Otherwise, the next five bytes must be interpreted as raw values.

Of course we are dealing with pixels now, so instead of the next byte, we'll use this for the next 3 bytes. Let's read the next line (skip the first 18 bytes then read 57):
hexdump -C -s 18 -n57 smiley.tga
97 66 44 22 0f 7a 53 41 9c 5b 75 b5 54 98 c5 48
af d1 3b bf d8 34 c7 da 30 cc db 2f cc da 30 cb
d8 34 c8 d4 39 c3 cd 41 b9 c2 4c ab b2 58 93 9a
5f 71 79 55 3f 97 66 44 22
The first byte 97 indicates compression (0x97 = 0x80 + 0x17) and that the next three bytes must be repeated 0x17 = 23 times. Or actually 24 times, since the repetition count zero indicates one repetition and so on. The following three bytes specify the pixel in BGR order. The 0f byte tells us no compression and that the next (0x0F + 1) * 3 = 48 bytes must be interpreted as raw pixel data. Finally (97) we have the same 24 pixels as in the beginning.
Also note how the tracking of repetitions stopped at the end of the line, even though we could have continued with the next, as it had the same deep blue color. This behaviour is specified (albeit kind of vaguely) in the TGA specification.
Endnote
We saw how RLE compression works, but also that we have to be careful how we represent our data. For texts should we store them as plain bytes, Unicode characters or raw bits and compress the ones and zeros? For images, should we parse them in row major or column major order, or maybe in zig-zag? Should we compress the red, green and blue channels separately? For these purposes there are more sophisticated and more universal compression methods, but they require some groundwork.
Sources
- TGA File Format Summary
- Murray, James D. , Van Ryper, William Encyclopedia of Graphics File Formats, 2nd Edition
- David Salomon Data Compression The Complete Reference Fourth Edition